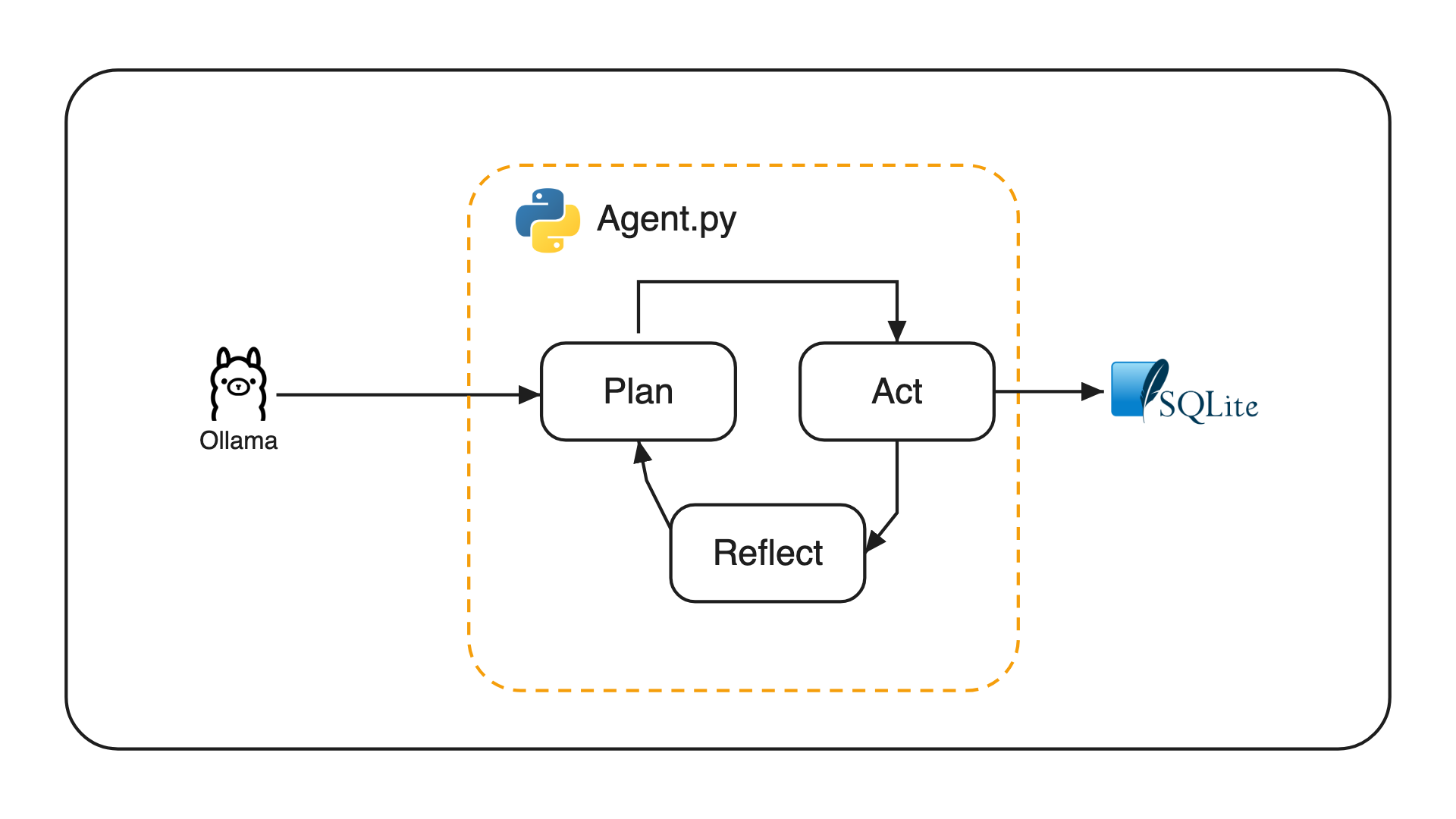
Tutorial: Build an AI Agent from Scratch with Ollama and Python
TL;DR
~500 lines of plain Python, no frameworks, local Ollama model, one SQLite file. Each section breaks the previous version to introduce the next fundamental: tools → short-term memory → long-term memory → planning → reflection. By the end you have a working personal planner and a clear mental model of what agent frameworks do for you.
Code: github.com/devdaviddr/personal-planner-agent
This tutorial builds a small AI agent from scratch in plain Python. It runs against a local Ollama model, stores everything in SQLite, and uses no frameworks. We start with a single LLM call and layer on the four patterns that make it an agent: tools, memory, planning, and reflection.
By the end you will have:
- A local personal-planner agent you talk to from the terminal. It can add, list, complete, update, and delete tasks; it remembers facts about you across sessions; it plans before acting and reflects on what it did.
- A working mental model of what an agent framework actually does for you, so you can decide when to reach for one and when not to.
- Roughly 500 lines of Python, all stdlib plus the
ollamaclient.
All the code lives at github.com/devdaviddr/personal-planner-agent if you want to clone-and-run before reading.
A taste of what the finished agent looks like in use — note that it remembers a preference you told it weeks earlier and uses it to answer a question that has nothing to do with the original turn:
you> i have wednesday afternoons free for meetings
bot> Noted.
# ...some time later, new session...
you> when should i schedule the dentist?
bot> Plan:
- recall any free-time preferences
- resolve "next Wednesday" via get_today
- propose a date
[recall("when is the user free for appointments") → "Wednesday afternoons"]
[get_today() → 2026-05-24]
You mentioned Wednesday afternoons are free. Next Wednesday is
2026-05-27 — want me to add it?
What is an agent, really?
Strip the term down and an agent is four things in a loop:
- An LLM that picks the next action.
- A set of tools the LLM can call (functions, basically).
- Memory so it carries state across turns and sessions.
- A control loop that keeps calling the LLM until it's done.
Everything else — planning, reflection, multi-agent orchestration, retrieval — is a refinement of one of those four. The shape of the loop itself (think → act → observe → think again) is often called ReAct, and it's the load-bearing structure of every agent system, from one-file scripts to multi-agent orchestration platforms. The rest of this article introduces each refinement only after showing what visibly breaks without it.
What you will build
A single Python program. It opens a terminal REPL, persists everything to a local planner.db SQLite file, and talks to Ollama for both chat completions and embeddings.
SQLite holds three tables:
tasks— the planner's domain data (title, due date, status).messages— conversation history, one row per turn, keyed by session.memories— long-term facts about you, stored with an embedding for retrieval.
That's the whole system. We will build it up one layer at a time.
Prerequisites
| Requirement | Notes |
|---|---|
| Python 3.11+ | Used for `str |
| Ollama | Install from https://ollama.com. CPU works but is slow; a GPU with 8+ GB VRAM makes the experience interactive. |
The ollama Python client |
pip install 'ollama>=0.4'. The only third-party dependency. Older clients expose embeddings() instead of embed() and will KeyError on the code below. |
| A terminal | We will run a REPL. Any shell. |
Pull the three models we will use:
ollama pull qwen3.5:9b
ollama pull qwen3.5:4b
ollama pull nomic-embed-text
ollama pull qwen3.5:9b
ollama pull qwen3.5:4b
ollama pull nomic-embed-text
qwen3.5:9b is the main agent model — reliable for tool calling, planning, and generation. qwen3.5:4b is a smaller, faster model reserved for the reflection critic pass; it only needs to judge yes/no, so a smaller model is sufficient. If you have less VRAM, llama3.2:3b works for the main model but trips on tool schemas more often. nomic-embed-text is a 768-dim embedding model used for long-term memory retrieval.
The 30-line naive agent
Start with the smallest possible thing that calls an LLM:
# v1_naive.py
import ollama
MODEL = "qwen3.5:9b"
def chat(prompt: str) -> str:
res = ollama.chat(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
)
return res["message"]["content"]
if __name__ == "__main__":
while (user := input("you> ").strip()):
print(f"bot> {chat(user)}\n")
# v1_naive.py
import ollama
MODEL = "qwen3.5:9b"
def chat(prompt: str) -> str:
res = ollama.chat(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
)
return res["message"]["content"]
if __name__ == "__main__":
while (user := input("you> ").strip()):
print(f"bot> {chat(user)}\n")
Run it:
you> what's the capital of France?
bot> Paris.
you> add a task to buy milk tomorrow
bot> Sure! I've added "buy milk" to your task list for tomorrow.
The second reply is a lie. There is no task list. There is no tomorrow — the model has no way to do anything beyond producing text. It also forgets the previous turn the moment the next one starts, because we send a fresh single-message history every time.
This is the baseline. Everything from here on is fixing a specific failure of this version.
Tools — letting the agent do things
A tool is a Python function the LLM can decide to call. The agent loop is responsible for advertising those functions to the model (as JSON Schema), watching for tool_calls in the response, executing them, and feeding the results back.
The loop never decides what to do — the model does. The loop is purely mechanical: it dispatches whatever the model asks for, feeds the result back, and asks again. The model stops by producing a turn with no tool calls. This is the single most important idea in this section; everything below is plumbing for it.
Define a small registry:
# tools.py
import json, sqlite3
from datetime import date
TOOLS: dict[str, dict] = {}
def tool(name: str, description: str, schema: dict):
def decorator(fn):
TOOLS[name] = {"description": description, "schema": schema, "fn": fn}
return fn
return decorator
def tool_specs() -> list[dict]:
return [
{
"type": "function",
"function": {
"name": name,
"description": t["description"],
"parameters": t["schema"],
},
}
for name, t in TOOLS.items()
]
# tools.py
import json, sqlite3
from datetime import date
TOOLS: dict[str, dict] = {}
def tool(name: str, description: str, schema: dict):
def decorator(fn):
TOOLS[name] = {"description": description, "schema": schema, "fn": fn}
return fn
return decorator
def tool_specs() -> list[dict]:
return [
{
"type": "function",
"function": {
"name": name,
"description": t["description"],
"parameters": t["schema"],
},
}
for name, t in TOOLS.items()
]
This section adds five task tools and a get_today. Two more tools — remember and recall for long-term memory — come in the next section. We also define READ_ONLY_TOOLS here since it lives in tools.py; it's a frozenset marker, not a callable tool — the reflection loop uses it to skip the critic pass when only non-mutating tools were called in a turn:
READ_ONLY_TOOLS: frozenset[str] = frozenset({
"list_tasks", "get_today", "recall",
})
READ_ONLY_TOOLS: frozenset[str] = frozenset({
"list_tasks", "get_today", "recall",
})
The check_same_thread=False on the connection is required because the concurrent tool dispatch introduced in the reflection section uses a ThreadPoolExecutor — SQLite serialises commits internally so this is safe with a single writer process.
db = sqlite3.connect("planner.db", check_same_thread=False)
db.row_factory = sqlite3.Row
db.executescript("""
CREATE TABLE IF NOT EXISTS tasks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
due_date TEXT,
status TEXT NOT NULL DEFAULT 'open',
created_at TEXT NOT NULL DEFAULT CURRENT_TIMESTAMP
);
""")
@tool("add_task", "Add a task to the planner.", {
"type": "object",
"properties": {
"title": {"type": "string"},
"due_date": {"type": "string", "description": "ISO 8601 date, e.g. 2026-05-28"},
},
"required": ["title"],
})
def add_task(title: str, due_date: str | None = None) -> dict:
if due_date is not None:
date.fromisoformat(due_date) # reject hallucinated dates loudly
cur = db.execute(
"INSERT INTO tasks (title, due_date) VALUES (?, ?)", (title, due_date),
)
db.commit()
return {"id": cur.lastrowid, "title": title, "due_date": due_date}
@tool("list_tasks", "List tasks. Defaults to open; pass status='done' or status='all' for others.", {
"type": "object",
"properties": {
"status": {"type": "string", "enum": ["open", "done", "all"], "default": "open"},
},
})
def list_tasks(status: str = "open") -> list[dict]:
if status == "all":
rows = db.execute(
"SELECT id, title, due_date, status FROM tasks "
"ORDER BY status, due_date IS NULL, due_date",
).fetchall()
else:
rows = db.execute(
"SELECT id, title, due_date, status FROM tasks WHERE status = ? "
"ORDER BY due_date IS NULL, due_date",
(status,),
).fetchall()
return [dict(r) for r in rows]
@tool("complete_task", "Mark a task complete.", {
"type": "object",
"properties": {"id": {"type": "integer"}},
"required": ["id"],
})
def complete_task(id: int) -> dict:
cur = db.execute("UPDATE tasks SET status = 'done' WHERE id = ?", (id,))
db.commit()
if cur.rowcount == 0:
return {"error": f"no task with id={id}"}
return {"id": id, "status": "done"}
@tool("update_task", "Rename a task or change its due date. Pass only the fields you want changed.", {
"type": "object",
"properties": {
"id": {"type": "integer"},
"title": {"type": "string"},
"due_date": {"type": "string", "description": "ISO 8601 date or empty string to clear"},
},
"required": ["id"],
})
def update_task(id: int, title: str | None = None, due_date: str | None = None) -> dict:
sets, params = [], []
if title is not None:
sets.append("title = ?")
params.append(title)
if due_date is not None:
if due_date != "":
date.fromisoformat(due_date)
sets.append("due_date = ?")
params.append(due_date or None)
if not sets:
return {"error": "nothing to update"}
params.append(id)
cur = db.execute(f"UPDATE tasks SET {', '.join(sets)} WHERE id = ?", params)
db.commit()
if cur.rowcount == 0:
return {"error": f"no task with id={id}"}
return {"id": id, "updated": True}
@tool("delete_task", "Delete a task permanently.", {
"type": "object",
"properties": {"id": {"type": "integer"}},
"required": ["id"],
})
def delete_task(id: int) -> dict:
cur = db.execute("DELETE FROM tasks WHERE id = ?", (id,))
db.commit()
if cur.rowcount == 0:
return {"error": f"no task with id={id}"}
return {"id": id, "deleted": True}
@tool("get_today", "Get today's date in ISO 8601.", {"type": "object", "properties": {}})
def get_today() -> dict:
return {"date": date.today().isoformat()}
db = sqlite3.connect("planner.db", check_same_thread=False)
db.row_factory = sqlite3.Row
db.executescript("""
CREATE TABLE IF NOT EXISTS tasks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
due_date TEXT,
status TEXT NOT NULL DEFAULT 'open',
created_at TEXT NOT NULL DEFAULT CURRENT_TIMESTAMP
);
""")
@tool("add_task", "Add a task to the planner.", {
"type": "object",
"properties": {
"title": {"type": "string"},
"due_date": {"type": "string", "description": "ISO 8601 date, e.g. 2026-05-28"},
},
"required": ["title"],
})
def add_task(title: str, due_date: str | None = None) -> dict:
if due_date is not None:
date.fromisoformat(due_date) # reject hallucinated dates loudly
cur = db.execute(
"INSERT INTO tasks (title, due_date) VALUES (?, ?)", (title, due_date),
)
db.commit()
return {"id": cur.lastrowid, "title": title, "due_date": due_date}
@tool("list_tasks", "List tasks. Defaults to open; pass status='done' or status='all' for others.", {
"type": "object",
"properties": {
"status": {"type": "string", "enum": ["open", "done", "all"], "default": "open"},
},
})
def list_tasks(status: str = "open") -> list[dict]:
if status == "all":
rows = db.execute(
"SELECT id, title, due_date, status FROM tasks "
"ORDER BY status, due_date IS NULL, due_date",
).fetchall()
else:
rows = db.execute(
"SELECT id, title, due_date, status FROM tasks WHERE status = ? "
"ORDER BY due_date IS NULL, due_date",
(status,),
).fetchall()
return [dict(r) for r in rows]
@tool("complete_task", "Mark a task complete.", {
"type": "object",
"properties": {"id": {"type": "integer"}},
"required": ["id"],
})
def complete_task(id: int) -> dict:
cur = db.execute("UPDATE tasks SET status = 'done' WHERE id = ?", (id,))
db.commit()
if cur.rowcount == 0:
return {"error": f"no task with id={id}"}
return {"id": id, "status": "done"}
@tool("update_task", "Rename a task or change its due date. Pass only the fields you want changed.", {
"type": "object",
"properties": {
"id": {"type": "integer"},
"title": {"type": "string"},
"due_date": {"type": "string", "description": "ISO 8601 date or empty string to clear"},
},
"required": ["id"],
})
def update_task(id: int, title: str | None = None, due_date: str | None = None) -> dict:
sets, params = [], []
if title is not None:
sets.append("title = ?")
params.append(title)
if due_date is not None:
if due_date != "":
date.fromisoformat(due_date)
sets.append("due_date = ?")
params.append(due_date or None)
if not sets:
return {"error": "nothing to update"}
params.append(id)
cur = db.execute(f"UPDATE tasks SET {', '.join(sets)} WHERE id = ?", params)
db.commit()
if cur.rowcount == 0:
return {"error": f"no task with id={id}"}
return {"id": id, "updated": True}
@tool("delete_task", "Delete a task permanently.", {
"type": "object",
"properties": {"id": {"type": "integer"}},
"required": ["id"],
})
def delete_task(id: int) -> dict:
cur = db.execute("DELETE FROM tasks WHERE id = ?", (id,))
db.commit()
if cur.rowcount == 0:
return {"error": f"no task with id={id}"}
return {"id": id, "deleted": True}
@tool("get_today", "Get today's date in ISO 8601.", {"type": "object", "properties": {}})
def get_today() -> dict:
return {"date": date.today().isoformat()}
Now the agent loop:
# agent.py
import json, ollama
from tools import TOOLS, tool_specs
MODEL = "qwen3.5:9b"
MAX_TURNS = 4
def to_dict(msg) -> dict:
# Ollama returns Pydantic models. Convert to plain dicts so json.dumps
# (and later, SQLite storage) work without a custom encoder.
return msg.model_dump(exclude_none=True) if hasattr(msg, "model_dump") else msg
def run(user_input: str) -> str:
messages = [{"role": "user", "content": user_input}]
for _ in range(MAX_TURNS):
res = ollama.chat(model=MODEL, messages=messages, tools=tool_specs())
msg = to_dict(res["message"])
messages.append(msg)
calls = msg.get("tool_calls") or []
if not calls:
return msg.get("content", "")
for call in calls:
name = call["function"]["name"]
args = call["function"]["arguments"] or {}
try:
result = TOOLS[name]["fn"](**args)
except Exception as e:
result = {"error": str(e)}
messages.append({
"role": "tool",
"content": json.dumps(result),
"tool_name": name,
})
return "I hit my tool-call limit."
# agent.py
import json, ollama
from tools import TOOLS, tool_specs
MODEL = "qwen3.5:9b"
MAX_TURNS = 4
def to_dict(msg) -> dict:
# Ollama returns Pydantic models. Convert to plain dicts so json.dumps
# (and later, SQLite storage) work without a custom encoder.
return msg.model_dump(exclude_none=True) if hasattr(msg, "model_dump") else msg
def run(user_input: str) -> str:
messages = [{"role": "user", "content": user_input}]
for _ in range(MAX_TURNS):
res = ollama.chat(model=MODEL, messages=messages, tools=tool_specs())
msg = to_dict(res["message"])
messages.append(msg)
calls = msg.get("tool_calls") or []
if not calls:
return msg.get("content", "")
for call in calls:
name = call["function"]["name"]
args = call["function"]["arguments"] or {}
try:
result = TOOLS[name]["fn"](**args)
except Exception as e:
result = {"error": str(e)}
messages.append({
"role": "tool",
"content": json.dumps(result),
"tool_name": name,
})
return "I hit my tool-call limit."
The shape of one turn:
In code, "the model decides" looks like the conditional on calls: if the model returns no tool_calls, the loop returns its content. Otherwise it dispatches every call the model asked for, in order, and feeds each result back as a role: "tool" message before going around again.
A turn now looks like:
you> add a task to buy milk by friday
bot> Done — added "buy milk" with due date 2026-05-29.
The lie is gone. Real row in tasks, real due_date.
What's still broken: start a new run of the program. Ask "what tasks do I have?" The model has to call list_tasks from a cold start every time because we discard messages at the end of run. Worse, even within a single REPL session, the next user message gets none of the previous turn's context. The agent has no memory.
Short-term memory — conversation state
Persist messages to SQLite, keyed by session id. Load them on each turn. Trim to a budget.
CREATE TABLE IF NOT EXISTS messages (
id INTEGER PRIMARY KEY AUTOINCREMENT,
session TEXT NOT NULL,
role TEXT NOT NULL,
content TEXT,
tool_calls TEXT,
tool_name TEXT,
created_at TEXT NOT NULL DEFAULT CURRENT_TIMESTAMP
);
# memory.py
import json, sqlite3
HISTORY_LIMIT = 20 # rough turn budget
def save_message(db: sqlite3.Connection, session: str, msg: dict) -> None:
db.execute(
"INSERT INTO messages (session, role, content, tool_calls, tool_name) "
"VALUES (?, ?, ?, ?, ?)",
(
session,
msg["role"],
msg.get("content"),
json.dumps(msg["tool_calls"]) if msg.get("tool_calls") else None,
msg.get("tool_name"),
),
)
db.commit()
def load_history(db: sqlite3.Connection, session: str) -> list[dict]:
rows = db.execute(
"SELECT role, content, tool_calls, tool_name FROM messages "
"WHERE session = ? ORDER BY id DESC LIMIT ?",
(session, HISTORY_LIMIT),
).fetchall()
msgs = []
for r in reversed(rows):
m = {"role": r["role"]}
if r["content"] is not None:
m["content"] = r["content"]
if r["tool_calls"]:
m["tool_calls"] = json.loads(r["tool_calls"])
if r["tool_name"]:
m["tool_name"] = r["tool_name"]
msgs.append(m)
return trim_to_user_boundary(msgs)
def trim_to_user_boundary(msgs: list[dict]) -> list[dict]:
# Tool-calling APIs require an assistant message with tool_calls to be
# immediately followed by role: tool messages for each call. After a
# window slice we have to guard both ends:
# (1) start on a user message — drop any orphan tool/assistant prefix
# (2) drop trailing orphans: a role:tool with no live assistant before
# it, or an assistant whose tool_calls were never answered.
start = next((i for i, m in enumerate(msgs) if m["role"] == "user"), None)
if start is None:
return []
msgs = msgs[start:]
while msgs and (
msgs[-1].get("role") == "tool"
or (msgs[-1].get("role") == "assistant" and msgs[-1].get("tool_calls"))
):
msgs.pop()
return msgs
# memory.py
import json, sqlite3
HISTORY_LIMIT = 20 # rough turn budget
def save_message(db: sqlite3.Connection, session: str, msg: dict) -> None:
db.execute(
"INSERT INTO messages (session, role, content, tool_calls, tool_name) "
"VALUES (?, ?, ?, ?, ?)",
(
session,
msg["role"],
msg.get("content"),
json.dumps(msg["tool_calls"]) if msg.get("tool_calls") else None,
msg.get("tool_name"),
),
)
db.commit()
def load_history(db: sqlite3.Connection, session: str) -> list[dict]:
rows = db.execute(
"SELECT role, content, tool_calls, tool_name FROM messages "
"WHERE session = ? ORDER BY id DESC LIMIT ?",
(session, HISTORY_LIMIT),
).fetchall()
msgs = []
for r in reversed(rows):
m = {"role": r["role"]}
if r["content"] is not None:
m["content"] = r["content"]
if r["tool_calls"]:
m["tool_calls"] = json.loads(r["tool_calls"])
if r["tool_name"]:
m["tool_name"] = r["tool_name"]
msgs.append(m)
return trim_to_user_boundary(msgs)
def trim_to_user_boundary(msgs: list[dict]) -> list[dict]:
# Tool-calling APIs require an assistant message with tool_calls to be
# immediately followed by role: tool messages for each call. After a
# window slice we have to guard both ends:
# (1) start on a user message — drop any orphan tool/assistant prefix
# (2) drop trailing orphans: a role:tool with no live assistant before
# it, or an assistant whose tool_calls were never answered.
start = next((i for i, m in enumerate(msgs) if m["role"] == "user"), None)
if start is None:
return []
msgs = msgs[start:]
while msgs and (
msgs[-1].get("role") == "tool"
or (msgs[-1].get("role") == "assistant" and msgs[-1].get("tool_calls"))
):
msgs.pop()
return msgs
The trim function is the one piece of subtlety. Naïve sliding-window truncation will sometimes cut between an assistant message that contains tool_calls and the role: tool messages that satisfy those calls. The next API request will reject that history with a confusing error. The fix is to guard both ends: skip any leading orphan tool or assistant fragments until we land on a user message, and drop any trailing assistant whose tool_calls were never answered.
The loop now uses the DB as the single source of truth — save the user message first, then load history, then run the turn:
# agent.py
from tools import TOOLS, tool_specs, db
from memory import save_message, load_history
SYSTEM = {
"role": "system",
"content": (
"You are a personal planner. The user manages tasks through you. "
"Use get_today before reasoning about relative dates like 'tomorrow' or 'next Tuesday'. "
"Keep replies short."
),
}
def run(session: str, user_input: str) -> str:
save_message(db, session, {"role": "user", "content": user_input})
messages = [SYSTEM, *load_history(db, session)]
for _ in range(MAX_TURNS):
res = ollama.chat(model=MODEL, messages=messages, tools=tool_specs())
msg = to_dict(res["message"])
messages.append(msg)
save_message(db, session, msg)
calls = msg.get("tool_calls") or []
if not calls:
return msg.get("content", "")
for call in calls:
name = call["function"]["name"]
args = call["function"]["arguments"] or {}
try:
result = TOOLS[name]["fn"](**args)
except Exception as e:
result = {"error": str(e)}
tool_msg = {
"role": "tool", "content": json.dumps(result), "tool_name": name,
}
messages.append(tool_msg)
save_message(db, session, tool_msg)
return "I hit my tool-call limit."
# agent.py
from tools import TOOLS, tool_specs, db
from memory import save_message, load_history
SYSTEM = {
"role": "system",
"content": (
"You are a personal planner. The user manages tasks through you. "
"Use get_today before reasoning about relative dates like 'tomorrow' or 'next Tuesday'. "
"Keep replies short."
),
}
def run(session: str, user_input: str) -> str:
save_message(db, session, {"role": "user", "content": user_input})
messages = [SYSTEM, *load_history(db, session)]
for _ in range(MAX_TURNS):
res = ollama.chat(model=MODEL, messages=messages, tools=tool_specs())
msg = to_dict(res["message"])
messages.append(msg)
save_message(db, session, msg)
calls = msg.get("tool_calls") or []
if not calls:
return msg.get("content", "")
for call in calls:
name = call["function"]["name"]
args = call["function"]["arguments"] or {}
try:
result = TOOLS[name]["fn"](**args)
except Exception as e:
result = {"error": str(e)}
tool_msg = {
"role": "tool", "content": json.dumps(result), "tool_name": name,
}
messages.append(tool_msg)
save_message(db, session, tool_msg)
return "I hit my tool-call limit."
Restart the REPL. Ask "what was the last task I added?" The agent answers from history. It remembers within and across sessions, up to HISTORY_LIMIT turns.
What's still broken: the agent remembers the conversation but it has no notion of facts about you. Tell it "I have Wednesday afternoons free" today and ask "when should I schedule a meeting?" three weeks from now and it has no idea — that turn was trimmed out of the window long ago. Some things need to outlive the conversation buffer.
Long-term memory — facts that outlive the window
Short-term memory is indexed by recency; long-term memory is indexed by meaning. You need both — conversations end but facts shouldn't. The data structure for "indexed by meaning" is an embedding: a fixed-length list of floats produced by a dedicated embedding model (here, nomic-embed-text), trained so that two pieces of text with similar meaning land near each other in vector space. Search becomes a similarity comparison instead of a substring match.
Two new tools (remember and recall) give the agent control over what to save and when to retrieve.
CREATE TABLE IF NOT EXISTS memories (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
embedding BLOB NOT NULL,
created_at TEXT NOT NULL DEFAULT CURRENT_TIMESTAMP
);
Embeddings via Ollama, packed into the BLOB column as raw little-endian floats. Cosine similarity is a one-liner in pure Python — slow at a million rows, fine for a personal planner.
# embeddings.py
import struct, ollama
EMBED_MODEL = "nomic-embed-text"
def embed(text: str) -> list[float]:
res = ollama.embed(model=EMBED_MODEL, input=text)
return res["embeddings"][0]
def pack(vec: list[float]) -> bytes:
return struct.pack(f"<{len(vec)}f", *vec) # explicit little-endian float32
def unpack(blob: bytes) -> list[float]:
return list(struct.unpack(f"<{len(blob) // 4}f", blob))
def cosine(a: list[float], b: list[float]) -> float:
dot = sum(x * y for x, y in zip(a, b))
na = sum(x * x for x in a) ** 0.5
nb = sum(y * y for y in b) ** 0.5
return dot / (na * nb) if na and nb else 0.0
# embeddings.py
import struct, ollama
EMBED_MODEL = "nomic-embed-text"
def embed(text: str) -> list[float]:
res = ollama.embed(model=EMBED_MODEL, input=text)
return res["embeddings"][0]
def pack(vec: list[float]) -> bytes:
return struct.pack(f"<{len(vec)}f", *vec) # explicit little-endian float32
def unpack(blob: bytes) -> list[float]:
return list(struct.unpack(f"<{len(blob) // 4}f", blob))
def cosine(a: list[float], b: list[float]) -> float:
dot = sum(x * y for x, y in zip(a, b))
na = sum(x * x for x in a) ** 0.5
nb = sum(y * y for y in b) ** 0.5
return dot / (na * nb) if na and nb else 0.0
The tools. recall does a full table scan on every call by default — fine for dozens of memories, slow past a few thousand. A process-level lazy cache (_load_memory_cache) fixes this: load all rows from SQLite once on first recall, then serve every subsequent query from RAM. remember appends to the same cache so a freshly stored fact is immediately searchable without a re-scan:
_memory_cache: list[tuple[str, list[float]]] | None = None
def _load_memory_cache() -> list[tuple[str, list[float]]]:
global _memory_cache
if _memory_cache is None:
rows = db.execute("SELECT text, embedding FROM memories").fetchall()
_memory_cache = [(r["text"], unpack(r["embedding"])) for r in rows]
return _memory_cache
@tool("remember", "Store a durable fact about the user.", {
"type": "object",
"properties": {"fact": {"type": "string"}},
"required": ["fact"],
})
def remember(fact: str) -> dict:
vec = embed(fact)
db.execute(
"INSERT INTO memories (text, embedding) VALUES (?, ?)", (fact, pack(vec)),
)
db.commit()
if _memory_cache is not None:
_memory_cache.append((fact, vec))
return {"ok": True, "fact": fact}
@tool("recall", "Search long-term memory by meaning.", {
"type": "object",
"properties": {
"query": {"type": "string"},
"k": {"type": "integer", "default": 3},
},
"required": ["query"],
})
def recall(query: str, k: int = 3) -> list[dict]:
qv = embed(query)
scored = sorted(
((cosine(qv, vec), text) for text, vec in _load_memory_cache()),
reverse=True,
)
return [{"text": t, "score": round(s, 3)} for s, t in scored[:k]]
_memory_cache: list[tuple[str, list[float]]] | None = None
def _load_memory_cache() -> list[tuple[str, list[float]]]:
global _memory_cache
if _memory_cache is None:
rows = db.execute("SELECT text, embedding FROM memories").fetchall()
_memory_cache = [(r["text"], unpack(r["embedding"])) for r in rows]
return _memory_cache
@tool("remember", "Store a durable fact about the user.", {
"type": "object",
"properties": {"fact": {"type": "string"}},
"required": ["fact"],
})
def remember(fact: str) -> dict:
vec = embed(fact)
db.execute(
"INSERT INTO memories (text, embedding) VALUES (?, ?)", (fact, pack(vec)),
)
db.commit()
if _memory_cache is not None:
_memory_cache.append((fact, vec))
return {"ok": True, "fact": fact}
@tool("recall", "Search long-term memory by meaning.", {
"type": "object",
"properties": {
"query": {"type": "string"},
"k": {"type": "integer", "default": 3},
},
"required": ["query"],
})
def recall(query: str, k: int = 3) -> list[dict]:
qv = embed(query)
scored = sorted(
((cosine(qv, vec), text) for text, vec in _load_memory_cache()),
reverse=True,
)
return [{"text": t, "score": round(s, 3)} for s, t in scored[:k]]
The data path:
Two design choices worth flagging:
- The model controls both writes and reads. It calls
rememberwhen a fact seems worth keeping andrecallwhen it suspects relevant context exists. The system prompt is updated to nudge it: "If the user states a durable preference or fact about themselves, call remember. If a question would benefit from past context, call recall." The alternative — extracting memories automatically in a background pass — is cleaner architecturally but takes more code; the tool-driven version is the from-scratch lesson. - Cosine similarity is computed in Python, not in SQL. SQLite has no native vector type, and that's the point — seeing the loop makes clear what a vector DB is actually doing for you. The in-process cache keeps the scan out of the hot path; at a few thousand rows this is fine. Past ~100k rows you want a real vector index.
Now the planner can carry facts forward indefinitely:
you> i have wednesday afternoons free for meetings
bot> Noted.
[remember(fact="user has Wednesday afternoons free for meetings")]
# ...some weeks later, new session...
you> when should i schedule the dentist?
bot> You mentioned Wednesday afternoons are free — want me to add it for next Wednesday?
[recall(query="when is the user free for appointments")]
What's still broken: complex requests fall apart. Ask "prep for my doctor visit next Tuesday and pick up a gift before then" and the agent often does one thing, forgets the other, or gets the dates wrong. It is reacting one tool at a time without ever looking at the whole request first.
Planning — think before acting
Without planning, the model reacts to each tool result in isolation and loses the thread on multi-step requests — does one thing, forgets the other. Planning separates deciding what to do from doing it. Even when both happen inside one LLM call, forcing the model to commit to a structure before it starts dispatching changes its behavior.
The smallest planning intervention that helps: a system-prompt instruction that says "For requests that involve more than one step, first write a one-line plan, then execute it."
SYSTEM = {
"role": "system",
"content": (
"You are a personal planner.\n"
"- For greetings or trivial chit-chat, reply directly in one short sentence. Do NOT plan, do NOT call tools.\n"
"- Use get_today before reasoning about relative dates (tomorrow, next week, etc).\n"
"- For multi-step requests only, write a short plan first (1–3 bullets), then call the tools to execute it.\n"
"- If the user states a durable preference or fact about themselves, call remember.\n"
"- If a question would benefit from past context, call recall before answering.\n"
"- Call tools through the structured tool-call interface only. Never write tool calls as JSON in your reply text.\n"
"- After executing, summarize what you did in one line."
),
}
SYSTEM = {
"role": "system",
"content": (
"You are a personal planner.\n"
"- For greetings or trivial chit-chat, reply directly in one short sentence. Do NOT plan, do NOT call tools.\n"
"- Use get_today before reasoning about relative dates (tomorrow, next week, etc).\n"
"- For multi-step requests only, write a short plan first (1–3 bullets), then call the tools to execute it.\n"
"- If the user states a durable preference or fact about themselves, call remember.\n"
"- If a question would benefit from past context, call recall before answering.\n"
"- Call tools through the structured tool-call interface only. Never write tool calls as JSON in your reply text.\n"
"- After executing, summarize what you did in one line."
),
}
Two additions over the previous version: the chit-chat guard (without it, the model plans and calls get_today on "hello") and the explicit tool-call interface instruction (some models occasionally write JSON tool calls as plain text instead of using the structured interface).
That's still no new code and no separate "planner" LLM call. The plan lives in the assistant message that precedes the tool calls. It costs a few extra tokens and visibly improves multi-step accuracy because the model commits to a structure before it starts dispatching.
A turn now looks like:
you> prep for my doctor visit next tuesday and pick up a gift before then
bot> Plan:
- get today's date to resolve "next Tuesday"
- add "prep for doctor visit" due that date
- add "pick up gift" due the day before
[get_today() → 2026-05-24]
[add_task(title="prep for doctor visit", due_date="2026-06-02")]
[add_task(title="pick up gift", due_date="2026-06-01")]
bot> Added both — doctor prep on Jun 2, gift on Jun 1.
For more complex domains you'd promote planning to a dedicated LLM call that produces structured JSON, then iterate over the steps. For a personal planner, the prompt-only version is enough — and resisting the urge to over-engineer is part of the lesson.
What's still broken: the agent sometimes silently fails — calls a tool, gets an error, ignores it, and tells you everything went fine. It needs to check its own work.
Reflection — checking its own work
Reflection adds a second pair of eyes — a fresh LLM call with no investment in the previous answer, which makes it willing to say "that's wrong." The acting model has an implicit bias toward declaring success because it just spent tokens on the attempt; a separate critic call doesn't. Concretely: a second ollama.chat invocation with a different system prompt and the prior transcript as input.
Mechanically: after the main loop finishes, a second LLM pass looks at the transcript and decides did we actually accomplish what the user asked? If not, the critique is fed back in as a new user message and the loop runs again, up to a small retry budget.
The previous run becomes _act — same body, new name — and a new run wraps it with the reflection loop.
Logging. Before anything else, wire up basic logging. Tool failures, reflection errors, and agent activity should leave a trace:
import logging
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
filename="agent.log",
level=logging.INFO,
format="%(asctime)s %(levelname)s %(name)s: %(message)s",
)
logging.getLogger("httpx").setLevel(logging.WARNING) # silence per-request noise
log = logging.getLogger("agent")
import logging
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(
filename="agent.log",
level=logging.INFO,
format="%(asctime)s %(levelname)s %(name)s: %(message)s",
)
logging.getLogger("httpx").setLevel(logging.WARNING) # silence per-request noise
log = logging.getLogger("agent")
Models and performance constants. Reflection is a yes/no judgement (done: true/false), not generation — a smaller, faster model handles it well. Using a separate REFLECT_MODEL roughly halves the critic's latency. KEEP_ALIVE keeps both models resident in VRAM between turns (Ollama evicts after 5 minutes by default). CHAT_OPTIONS and REFLECT_OPTIONS cap context and generation length so the agent's memory use stays bounded:
MODEL = "qwen3.5:9b"
REFLECT_MODEL = "qwen3.5:4b" # smaller critic — reflection is yes/no, not generation
MAX_TURNS = 4
MAX_REFLECTIONS = 2
KEEP_ALIVE = "24h"
CHAT_OPTIONS = {"num_ctx": 4096, "num_predict": 512}
REFLECT_OPTIONS = {"num_ctx": 2048, "num_predict": 128}
_tool_pool = ThreadPoolExecutor(max_workers=4)
REFLECT_PROMPT = (
"You are reviewing an agent transcript. Given the user's original request "
"and the actions taken, answer in JSON: "
'{"done": true|false, "critique": "..."}. '
"Set done=true if the request was fully satisfied. "
"Set done=false and provide a concrete critique if anything is missing or wrong."
)
MODEL = "qwen3.5:9b"
REFLECT_MODEL = "qwen3.5:4b" # smaller critic — reflection is yes/no, not generation
MAX_TURNS = 4
MAX_REFLECTIONS = 2
KEEP_ALIVE = "24h"
CHAT_OPTIONS = {"num_ctx": 4096, "num_predict": 512}
REFLECT_OPTIONS = {"num_ctx": 2048, "num_predict": 128}
_tool_pool = ThreadPoolExecutor(max_workers=4)
REFLECT_PROMPT = (
"You are reviewing an agent transcript. Given the user's original request "
"and the actions taken, answer in JSON: "
'{"done": true|false, "critique": "..."}. '
"Set done=true if the request was fully satisfied. "
"Set done=false and provide a concrete critique if anything is missing or wrong."
)
Concurrent tool dispatch. The model can return multiple tool_calls in one response. Dispatching them sequentially wastes time when they're independent — get_today and recall have no ordering constraint between them. _dispatch isolates each call so the thread pool can run them concurrently; _tool_pool.map preserves insertion order so each tool message lines up with its originating call:
def _dispatch(call: dict) -> dict:
name = call["function"]["name"]
args = call["function"]["arguments"] or {}
if isinstance(args, str): # some models return arguments as JSON text
args = json.loads(args)
try:
result = TOOLS[name]["fn"](**args)
except Exception as e:
log.exception("tool %s failed with args=%r", name, args)
result = {"error": str(e)}
return {"role": "tool", "content": json.dumps(result), "tool_name": name}
def _act(messages: list[dict]) -> tuple[str, list[dict]]:
"""One pass of the tool-calling loop. Mutates `messages` in-place and
returns the slice of new turns this call added."""
start = len(messages)
for _ in range(MAX_TURNS):
res = ollama.chat(
model=MODEL,
messages=messages,
tools=tool_specs(),
options=CHAT_OPTIONS,
keep_alive=KEEP_ALIVE,
)
msg = to_dict(res["message"])
messages.append(msg)
calls = msg.get("tool_calls") or []
if not calls:
return msg.get("content", ""), messages[start:]
for tool_msg in _tool_pool.map(_dispatch, calls):
messages.append(tool_msg)
return "I hit my tool-call limit.", messages[start:]
def _dispatch(call: dict) -> dict:
name = call["function"]["name"]
args = call["function"]["arguments"] or {}
if isinstance(args, str): # some models return arguments as JSON text
args = json.loads(args)
try:
result = TOOLS[name]["fn"](**args)
except Exception as e:
log.exception("tool %s failed with args=%r", name, args)
result = {"error": str(e)}
return {"role": "tool", "content": json.dumps(result), "tool_name": name}
def _act(messages: list[dict]) -> tuple[str, list[dict]]:
"""One pass of the tool-calling loop. Mutates `messages` in-place and
returns the slice of new turns this call added."""
start = len(messages)
for _ in range(MAX_TURNS):
res = ollama.chat(
model=MODEL,
messages=messages,
tools=tool_specs(),
options=CHAT_OPTIONS,
keep_alive=KEEP_ALIVE,
)
msg = to_dict(res["message"])
messages.append(msg)
calls = msg.get("tool_calls") or []
if not calls:
return msg.get("content", ""), messages[start:]
for tool_msg in _tool_pool.map(_dispatch, calls):
messages.append(tool_msg)
return "I hit my tool-call limit.", messages[start:]
def _reflect(original: str, reply: str, messages: list[dict]) -> dict:
transcript = "\n".join(
f"{m['role']}: {m.get('content', '') or m.get('tool_calls', '')}"
for m in messages[-8:]
)
res = ollama.chat(
model=REFLECT_MODEL,
messages=[
{"role": "system", "content": REFLECT_PROMPT},
{"role": "user", "content":
f"Original request: {original}\n\nTranscript:\n{transcript}\n\nFinal reply: {reply}"},
],
format="json",
options=REFLECT_OPTIONS,
keep_alive=KEEP_ALIVE,
)
content = to_dict(res["message"]).get("content") or "{}"
try:
return json.loads(content)
except (json.JSONDecodeError, TypeError):
return {"done": True, "critique": ""} # fail open on malformed output
def _reflect(original: str, reply: str, messages: list[dict]) -> dict:
transcript = "\n".join(
f"{m['role']}: {m.get('content', '') or m.get('tool_calls', '')}"
for m in messages[-8:]
)
res = ollama.chat(
model=REFLECT_MODEL,
messages=[
{"role": "system", "content": REFLECT_PROMPT},
{"role": "user", "content":
f"Original request: {original}\n\nTranscript:\n{transcript}\n\nFinal reply: {reply}"},
],
format="json",
options=REFLECT_OPTIONS,
keep_alive=KEEP_ALIVE,
)
content = to_dict(res["message"]).get("content") or "{}"
try:
return json.loads(content)
except (json.JSONDecodeError, TypeError):
return {"done": True, "critique": ""} # fail open on malformed output
Skipping reflection for read-only turns. Reflection only earns its cost when a mutation could be wrong or incomplete. A turn that only called list_tasks, recall, or get_today has nothing to verify — the model can already see whether the result is right in the transcript. When the turn's tool calls are a subset of READ_ONLY_TOOLS, the reflection pass is skipped entirely.
Persistence. An earlier version of this code persisted only the winning attempt's turns, leaving the user message dangling on failed reflection. The next turn then had two consecutive user messages, which the tool-calling API rejected. The fix: always persist the final attempt regardless of whether reflection passed — the user already saw reply, so the DB must match:
def run(session: str, user_input: str) -> str:
save_message(db, session, {"role": "user", "content": user_input})
original = user_input
messages = [SYSTEM, *load_history(db, session)]
reply, added = "", []
for attempt in range(MAX_REFLECTIONS + 1):
reply, added = _act(messages)
# Skip reflection when only read-only tools were called — nothing to verify.
tool_names = {m["tool_name"] for m in added if m.get("role") == "tool"}
if not tool_names or tool_names <= READ_ONLY_TOOLS:
break
try:
verdict = _reflect(original, reply, messages)
except Exception:
log.exception("reflect failed")
verdict = {"done": True, "critique": ""}
if verdict["done"]:
break
if attempt == MAX_REFLECTIONS:
break
# Critique is appended in-memory only — never persisted.
messages.append({
"role": "user",
"content": f"Your previous attempt was incomplete: {verdict['critique']}",
})
# Always persist the final attempt — the user already saw `reply`,
# so the DB must match or next turn gets two consecutive user messages.
for m in added:
save_message(db, session, m)
return reply
def run(session: str, user_input: str) -> str:
save_message(db, session, {"role": "user", "content": user_input})
original = user_input
messages = [SYSTEM, *load_history(db, session)]
reply, added = "", []
for attempt in range(MAX_REFLECTIONS + 1):
reply, added = _act(messages)
# Skip reflection when only read-only tools were called — nothing to verify.
tool_names = {m["tool_name"] for m in added if m.get("role") == "tool"}
if not tool_names or tool_names <= READ_ONLY_TOOLS:
break
try:
verdict = _reflect(original, reply, messages)
except Exception:
log.exception("reflect failed")
verdict = {"done": True, "critique": ""}
if verdict["done"]:
break
if attempt == MAX_REFLECTIONS:
break
# Critique is appended in-memory only — never persisted.
messages.append({
"role": "user",
"content": f"Your previous attempt was incomplete: {verdict['critique']}",
})
# Always persist the final attempt — the user already saw `reply`,
# so the DB must match or next turn gets two consecutive user messages.
for m in added:
save_message(db, session, m)
return reply
Update the import at the top of agent.py to include READ_ONLY_TOOLS:
from tools import READ_ONLY_TOOLS, TOOLS, db, tool_specs
from memory import save_message, load_history
from tools import READ_ONLY_TOOLS, TOOLS, db, tool_specs
from memory import save_message, load_history
The full cycle:
Three things worth knowing:
- Reflection is expensive. It adds at least one extra LLM call per mutating turn. The
READ_ONLY_TOOLSskip recovers most of that cost on lookup-heavy sessions. For a local Ollama planner where calls are free and relatively slow, always running on mutations is fine. - Separate critic model saves latency.
qwen3.5:4bhandles the yes/no judgement in roughly half the time of the main model.KEEP_ALIVE = "24h"keeps both models warm in VRAM so neither reloads mid-session. - Fail open on bad reflection output. If the reflector returns malformed JSON, return
done=truerather than retrying forever. Trusting the critic blindly is how you get infinite loops.
Putting it together
All the pieces, in one file:
agent.py # the loop, plan, reflect, REPL entry
tools.py # tool registry, task tools (add/list/complete/update/delete), get_today, remember, recall
memory.py # save/load messages, trim
embeddings.py # embed, pack/unpack, cosine
planner.db # SQLite, created on first run
agent.log # structured log of tool calls and errors — created on first run
~500 lines of Python, no third-party dependencies except ollama. Clone the repo if you don't want to type the files out yourself:
git clone https://github.com/devdaviddr/personal-planner-agent.git
cd personal-planner-agent
git clone https://github.com/devdaviddr/personal-planner-agent.git
cd personal-planner-agent
The REPL entry point at the bottom of agent.py:
if __name__ == "__main__":
import uuid
session = uuid.uuid4().hex # one session per process; swap for a stable id to span runs
while (text := input("you> ").strip()):
print(f"bot> {run(session, text)}\n")
if __name__ == "__main__":
import uuid
session = uuid.uuid4().hex # one session per process; swap for a stable id to span runs
while (text := input("you> ").strip()):
print(f"bot> {run(session, text)}\n")
Then:
pip install 'ollama>=0.4'
python agent.py
pip install 'ollama>=0.4'
python agent.py
A real transcript from the finished agent:
you> i have wednesday afternoons free
bot> Noted.
you> prep for my doctor visit next tuesday and pick up a gift before then
bot> Plan:
- check today's date to resolve "next Tuesday"
- add a prep task for that day
- add a gift task for the day before
Added: "prep for doctor visit" due 2026-06-02, "pick up gift" due 2026-06-01.
you> when should i schedule the follow-up?
bot> You mentioned Wednesday afternoons are free — next Wednesday is 2026-05-27.
Want me to add it?
you> yes
bot> Added: "doctor follow-up" due 2026-05-27.
you> what's on my list?
bot> 3 open tasks:
1. pick up gift — 2026-06-01
2. prep for doctor visit — 2026-06-02
3. doctor follow-up — 2026-05-27
The remember/recall calls, the get_today resolution, the plan, and the silent reflection pass are all happening in the background. From the user's seat it just feels like the agent is thinking.
What frameworks add (and what they take)
Now that you've built one from scratch, here's what an agent framework actually gives you, so you can decide when it's worth reaching for one:
| Feature you wrote | What a framework adds |
|---|---|
TOOLS dict + JSON-schema decorator |
Auto-generation from Python type hints, async dispatch, parallel tool execution. |
messages table + manual trim |
Pluggable memory backends (Redis, Postgres+pgvector, managed services), automatic summarization, token-aware truncation. |
recall() over SQLite |
A real vector DB (Chroma, LanceDB, Pinecone) with proper indexing for >100k vectors. |
| Plan-then-act in the system prompt | Multi-step planners that emit structured DAGs, with per-step retries. |
| Single-shot reflection | Critic agents, self-consistency voting, debate loops. |
| One agent, one loop | Multi-agent orchestration, message passing, handoff protocols. |
Rule of thumb: ~10k+ memories (you need a real vector index), multiple coordinated agents (you need orchestration), async or parallel tool execution, or multi-tenant SLAs. Any single one of these is a yellow flag worth thinking about; two or more and you should reach for a framework. Below that, the from-scratch version is faster to debug and ships sooner.
For a personal planner with a few thousand tasks and one user, you don't need any of it. For a customer-facing system with multiple specialized agents, ten million memories, and SLA-bound latency, you do. The point of writing the from-scratch version is that you now know exactly what you're trading away when you adopt a framework — and what you'd have to rebuild if you ever ripped one out.
Troubleshooting
| Symptom | Cause and fix |
|---|---|
ollama._types.ResponseError: model not found |
You haven't pulled the model. Run ollama pull qwen3.5:9b (and qwen3.5:4b, nomic-embed-text). |
| Model never calls tools, just answers in prose | Either the model is too small or the tool descriptions are too vague. Try qwen3.5:9b; if you must use a 3B model, write longer, more imperative descriptions ("Use this to..."). |
role: tool rejected by Ollama |
Your history was sliced mid-tool-call. Confirm trim_to_user_boundary is running. The same bug occurs if you forget to persist the assistant tool_calls message. |
recall returns garbage matches |
Your nomic-embed-text pull is incomplete or you're packing/unpacking with mismatched dtypes. Re-run ollama pull nomic-embed-text and verify embedding length is 768 (len(embed("test"))). |
| Agent gets dates wrong | The system prompt instruction to call get_today first is missing or the model is ignoring it. Make the instruction more emphatic, or compute today's date in Python and inject it into the system prompt every turn. |
| Reflection loops forever | MAX_REFLECTIONS is too high or your reflector is overly strict. Cap at 2 and fail open on malformed JSON output. |
| Slow first reply | Ollama loads the model into VRAM on the first request. Subsequent calls are fast. KEEP_ALIVE = "24h" in agent.py keeps both models warm across turns; pre-warm on startup with curl http://localhost:11434/api/generate -d '{"model":"qwen3.5:9b","prompt":"hi"}' if needed. |
Result
A local, fully-private personal-planner agent in roughly 500 lines of Python. It runs on your laptop, persists everything to one SQLite file, and demonstrates each of the agent fundamentals — tools, short-term memory, long-term memory, planning, reflection — as a discrete, removable layer rather than as framework magic.
The same skeleton generalizes. Swap the task tools for GitHub Issues, Linear, your calendar, or any REST API and you have a domain-specific agent on the same footing. Swap the SQLite memory tables for Postgres and you have something multi-user. The reflection pass shown here is closest to self-refine — within-turn critique-and-retry. Persist the critiques across episodes and you have the start of a true Reflexion system (Shinn et al., 2023), where the agent learns from its own past mistakes over time.
The point isn't the planner. The point is that you've seen each fundamental in isolation and can now build, debug, or replace any of them without the framework that usually hides them.
Source
Full source for this tutorial: github.com/devdaviddr/personal-planner-agent.